libtorrent manual
| Author: | Arvid Norberg, arvid@rasterbar.com |
|---|---|
| Version: | 1.0.0 |
Table of contents
tuning libtorrent
libtorrent expose most constants used in the bittorrent engine for customization through the session_settings. This makes it possible to test and tweak the parameters for certain algorithms to make a client that fits a wide range of needs. From low memory embedded devices to servers seeding thousands of torrents. The default settings in libtorrent are tuned for an end-user bittorrent client running on a normal desktop computer.
This document describes techniques to benchmark libtorrent performance and how parameters are likely to affect it.
reducing memory footprint
These are things you can do to reduce the memory footprint of libtorrent. You get some of this by basing your default session_settings on the min_memory_usage() setting preset function.
Keep in mind that lowering memory usage will affect performance, always profile and benchmark your settings to determine if it's worth the trade-off.
The typical buffer usage of libtorrent, for a single download, with the cache size set to 256 blocks (256 * 16 kiB = 4 MiB) is:
read cache: 128.6 (2058 kiB) write cache: 103.5 (1656 kiB) receive buffers: 7.3 (117 kiB) send buffers: 4.8 (77 kiB) hash temp: 0.001 (19 Bytes)
The receive buffers is proportional to the number of connections we make, and is limited by the total number of connections in the session (default is 200).
The send buffers is proportional to the number of upload slots that are allowed in the session. The default is auto configured based on the observed upload rate.
The read and write cache can be controlled (see section below).
The "hash temp" entry size depends on whether or not hashing is optimized for speed or memory usage. In this test run it was optimized for memory usage.
disable disk cache
The bulk of the memory libtorrent will use is used for the disk cache. To save the absolute most amount of memory, you can disable the cache by setting session_settings::cache_size to 0. You might want to consider using the cache but just disable caching read operations. You do this by settings session_settings::use_read_cache to false. This is the main factor in how much memory will be used by the client. Keep in mind that you will degrade performance by disabling the cache. You should benchmark the disk access in order to make an informed trade-off.
remove torrents
Torrents that have been added to libtorrent will inevitably use up memory, even when it's paused. A paused torrent will not use any peer connection objects or any send or receive buffers though. Any added torrent holds the entire .torrent file in memory, it also remembers the entire list of peers that it's heard about (which can be fairly long unless it's capped). It also retains information about which blocks and pieces we have on disk, which can be significant for torrents with many pieces.
If you need to minimize the memory footprint, consider removing torrents from the session rather than pausing them. This will likely only make a difference when you have a very large number of torrents in a session.
The downside of removing them is that they will no longer be auto-managed. Paused auto managed torrents are scraped periodically, to determine which torrents are in the greatest need of seeding, and libtorrent will prioritize to seed those.
socket buffer sizes
You can make libtorrent explicitly set the kernel buffer sizes of all its peer sockets. If you set this to a low number, you may see reduced throughput, especially for high latency connections. It is however an opportunity to save memory per connection, and might be worth considering if you have a very large number of peer connections. This memory will not be visible in your process, this sets the amount of kernel memory is used for your sockets.
Change this by setting session_settings::recv_socket_buffer_size and session_settings::send_socket_buffer_size.
peer list size
The default maximum for the peer list is 4000 peers. For IPv4 peers, each peer entry uses 32 bytes, which ends up using 128 kB per torrent. If seeding 4 popular torrents, the peer lists alone uses about half a megabyte.
The default limit is the same for paused torrents as well, so if you have a large number of paused torrents (that are popular) it will be even more significant.
If you're short of memory, you should consider lowering the limit. 500 is probably enough. You can do this by setting session_settings::max_peerlist_size to the max number of peers you want in the torrent's peer list.
You should also lower the same limit but for paused torrents. It might even make sense to set that even lower, since you only need a few peers to start up while waiting for the tracker and DHT to give you fresh ones. The max peer list size for paused torrents is set by session_settings::max_paused_peerlist_size.
The drawback of lowering this number is that if you end up in a position where the tracker is down for an extended period of time, your only hope of finding live peers is to go through your list of all peers you've ever seen. Having a large peer list will also help increase performance when starting up, since the torrent can start connecting to peers in parallel with connecting to the tracker.
send buffer watermark
The send buffer watermark controls when libtorrent will ask the disk I/O thread to read blocks from disk, and append it to a peer's send buffer.
When the send buffer has fewer than or equal number of bytes as session_settings::send_buffer_watermark, the peer will ask the disk I/O thread for more data to send. The trade-off here is between wasting memory by having too much data in the send buffer, and hurting send rate by starving out the socket, waiting for the disk read operation to complete.
If your main objective is memory usage and you're not concerned about being able to achieve high send rates, you can set the watermark to 9 bytes. This will guarantee that no more than a single (16 kiB) block will be on the send buffer at a time, for all peers. This is the least amount of memory possible for the send buffer.
You should benchmark your max send rate when adjusting this setting. If you have a very fast disk, you are less likely see a performance hit.
optimize hashing for memory usage
When libtorrent is doing hash checks of a file, or when it re-reads a piece that was just completed to verify its hash, there are two options. The default one is optimized for speed, which allocates buffers for the entire piece, reads in the whole piece in one read call, then hashes it.
The second option is to optimize for memory usage instead, where a single buffer is allocated, and the piece is read one block at a time, hashing it as each block is read from the file. For low memory environments, this latter approach is recommended. Change this by settings session_settings::optimize_hashing_for_speed to false. This will significantly reduce peak memory usage, especially for torrents with very large pieces.
reduce executable size
Compilers generally add a significant number of bytes to executables that make use of C++ exceptions. By disabling exceptions (-fno-exceptions on GCC), you can reduce the executable size with up to 45%. In order to build without exception support, you need to patch parts of boost.
Also make sure to optimize for size when compiling.
Another way of reducing the executable size is to disable code that isn't used. There are a number of TORRENT_* macros that control which features are included in libtorrent. If these macros are used to strip down libtorrent, make sure the same macros are defined when building libtorrent as when linking against it. If these are different the structures will look different from the libtorrent side and from the client side and memory corruption will follow.
One, probably, safe macro to define is TORRENT_NO_DEPRECATE which removes all deprecated functions and struct members. As long as no deprecated functions are relied upon, this should be a simple way to eliminate a little bit of code.
For all available options, see the building libtorrent secion.
reduce statistics
You can save some memory for each connection and each torrent by reducing the number of separate rates kept track of by libtorrent. If you build with full-stats=off (or -DTORRENT_DISABLE_FULL_STATS) you will save a few hundred bytes for each connection and torrent. It might make a difference if you have a very large number of peers or torrents.
play nice with the disk
When checking a torrent, libtorrent will try to read as fast as possible from the disk. The only thing that might hold it back is a CPU that is slow at calculating SHA-1 hashes, but typically the file checking is limited by disk read speed. Most operating systems today do not prioritize disk access based on the importance of the operation, this means that checking a torrent might delay other disk accesses, such as virtual memory swapping or just loading file by other (interactive) applications.
In order to play nicer with the disk, and leave some spare time for it to service other processes that might be of higher importance to the end-user, you can introduce a sleep between the disc accesses. This is a direct tradeoff between how fast you can check a torrent and how soft you will hit the disk.
You control this by setting the session_settings::file_checks_delay_per_block to greater than zero. This number is the number of milliseconds to sleep between each read of 16 kiB.
The sleeps are not necessarily in between each 16 kiB block (it might be read in larger chunks), but the number will be multiplied by the number of blocks that were read, to maintain the same semantics.
high performance seeding
In the case of a high volume seed, there are two main concerns. Performance and scalability. This translates into high send rates, and low memory and CPU usage per peer connection.
file pool
libtorrent keeps an LRU file cache. Each file that is opened, is stuck in the cache. The main purpose of this is because of anti-virus software that hooks on file-open and file close to scan the file. Anti-virus software that does that will significantly increase the cost of opening and closing files. However, for a high performance seed, the file open/close might be so frequent that it becomes a significant cost. It might therefore be a good idea to allow a large file descriptor cache. Adjust this though session_settings::file_pool_size.
Don't forget to set a high rlimit for file descriptors in your process as well. This limit must be high enough to keep all connections and files open.
disk cache
You typically want to set the cache size to as high as possible. The session_settings::cache_size is specified in 16 kiB blocks. Since you're seeding, the cache would be useless unless you also set session_settings::use_read_cache to true.
In order to increase the possibility of read cache hits, set the session_settings::cache_expiry to a large number. This won't degrade anything as long as the client is only seeding, and not downloading any torrents.
In order to increase the disk cache hit rate, you can enable suggest messages based on what's in the read cache. To do this, set session_settings::suggest_mode to session_settings::suggest_read_cache. This will send suggest messages to peers for the most recently used pieces in the read cache. This is especially useful if you also enable explicit read cache, by settings session_settings::explicit_read_cache to the number of pieces to keep in the cache. The explicit read cache will make the disk read cache stick, and not be evicted by cache misses. The explicit read cache will automatically pull in the rarest pieces in the read cache.
Assuming that you seed much more data than you can keep in the cache, to a large numbers of peers (so that the read cache wouldn't be useful anyway), this may be a good idea.
When peers first connect, libtorrent will send them a number of allow-fast messages, which lets the peers download certain pieces even when they are choked, since peers are choked by default, this often triggers immediate requests for those pieces. In the case of using explicit read cache and suggesting those pieces, allowing fast pieces should be disabled, to not systematically trigger requests for pieces that are not cached for all peers. You can turn off allow-fast by settings session_settings::allowed_fast_set_size to 0.
As an alternative to the explicit cache and suggest messages, there's a guided cache mode. This means the size of the read cache line that's stored in the cache is determined based on the upload rate to the peer that triggered the read operation. The idea being that slow peers don't use up a disproportional amount of space in the cache. This is enabled through session_settings::guided_read_cache.
In cases where the assumption is that the cache is only used as a read-ahead, and that no other peer will ever request the same block while it's still in the cache, the read cache can be set to be volatile. This means that every block that is requested out of the read cache is removed immediately. This saves a significant amount of cache space which can be used as read-ahead for other peers. This mode should never be combined with either explicit_read_cache or suggest_read_cache, since those uses opposite strategies for the read cache. You don't want to on one hand attract peers to request the same pieces, and on the other hand assume that they won't request the same pieces and drop them when the first peer requests it. To enable volatile read cache, set session_settings::volatile_read_cache to true.
uTP-TCP mixed mode
libtorrent supports uTP, which has a delay based congestion controller. In order to avoid having a single TCP bittorrent connection completely starve out any uTP connection, there is a mixed mode algorithm. This attempts to detect congestion on the uTP peers and throttle TCP to avoid it taking over all bandwidth. This balances the bandwidth resources between the two protocols. When running on a network where the bandwidth is in such an abundance that it's virtually infinite, this algorithm is no longer necessary, and might even be harmful to throughput. It is adviced to experiment with the session_setting::mixed_mode_algorithm, setting it to session_settings::prefer_tcp. This setting entirely disables the balancing and unthrottles all connections. On a typical home connection, this would mean that none of the benefits of uTP would be preserved (the modem's send buffer would be full at all times) and uTP connections would for the most part be squashed by the TCP traffic.
send buffer low watermark
libtorrent uses a low watermark for send buffers to determine when a new piece should be requested from the disk I/O subsystem, to be appended to the send buffer. The low watermark is determined based on the send rate of the socket. It needs to be large enough to not draining the socket's send buffer before the disk operation completes.
The watermark is bound to a max value, to avoid buffer sizes growing out of control. The default max send buffer size might not be enough to sustain very high upload rates, and you might have to increase it. It's specified in bytes in session_settings::send_buffer_watermark. The high_performance_seed() preset sets this value to 5 MB.
peers
First of all, in order to allow many connections, set the global connection limit high, session::set_max_connections(). Also set the upload rate limit to infinite, session::set_upload_rate_limit(), passing 0 means infinite.
When dealing with a large number of peers, it might be a good idea to have slightly stricter timeouts, to get rid of lingering connections as soon as possible.
There are a couple of relevant settings: session_settings::request_timeout, session_settings::peer_timeout and session_settings::inactivity_timeout.
For seeds that are critical for a delivery system, you most likely want to allow multiple connections from the same IP. That way two people from behind the same NAT can use the service simultaneously. This is controlled by session_settings::allow_multiple_connections_per_ip.
In order to always unchoke peers, turn off automatic unchoke session_settings::auto_upload_slots and set the number of upload slots to a large number via session::set_max_uploads(), or use -1 (which means infinite).
torrent limits
To seed thousands of torrents, you need to increase the session_settings::active_limit and session_settings::active_seeds.
scalability
In order to make more efficient use of the libtorrent interface when running a large number of torrents simultaneously, one can use the session::get_torrent_status() call together with session::refresh_torrent_status(). Keep in mind that every call into libtorrent that return some value have to block your thread while posting a message to the main network thread and then wait for a response (calls that don't return any data will simply post the message and then immediately return). The time this takes might become significant once you reach a few hundred torrents (depending on how many calls you make to each torrent and how often). get_torrent_status lets you query the status of all torrents in a single call. This will actually loop through all torrents and run a provided predicate function to determine whether or not to include it in the returned vector. If you have a lot of torrents, you might want to update the status of only certain torrents. For instance, you might only be interested in torrents that are being downloaded.
The intended use of these functions is to start off by calling get_torrent_status to get a list of all torrents that match your criteria. Then call refresh_torrent_status on that list. This will only refresh the status for the torrents in your list, and thus ignore all other torrents you might be running. This may save a significant amount of time, especially if the number of torrents you're interested in is small. In order to keep your list of interested torrents up to date, you can either call get_torrent_status from time to time, to include torrents you might have become interested in since the last time. In order to stop refreshing a certain torrent, simply remove it from the list.
A more efficient way however, would be to subscribe to status alert notifications, and update your list based on these alerts. There are alerts for when torrents are added, removed, paused, resumed, completed etc. Doing this ensures that you only query status for the minimal set of torrents you are actually interested in.
benchmarking
There is a bunch of built-in instrumentation of libtorrent that can be used to get an insight into what it's doing and how well it performs. This instrumentation is enabled by defining preprocessor symbols when building.
There are also a number of scripts that parses the log files and generates graphs (requires gnuplot and python).
disk metrics
To enable disk I/O instrumentation, define TORRENT_DISK_STATS when building. When built with this configuration libtorrent will create three log files, measuring various aspects of the disk I/O. The following table is an overview of these files and what they measure.
| filename | description |
|---|---|
| disk_io_thread.log | This is a log of which operation the disk I/O thread is engaged in, with timestamps. This tells you what the thread is spending its time doing. |
| disk_buffers.log | This log keeps track of what the buffers allocated from the disk buffer pool are used for. There are 5 categories. receive buffer, send buffer, write cache, read cache and temporary hash storage. This is key when optimizing memory usage. |
| disk_access.log | This is a low level log of read and write operations, with timestamps and file offsets. The file offsets are byte offsets in the torrent (not in any particular file, in the case of a multi-file torrent). This can be used as an estimate of the physical drive location. The purpose of this log is to identify the amount of seeking the drive has to do. |
disk_io_thread.log
The structure of this log is simple. For each line, there are two columns, a timestamp and the operation that was started. There is a special operation called idle which means it looped back to the top and started waiting for new jobs. If there are more jobs to handle immediately, the idle state is still there, but the timestamp is the same as the next job that is handled.
Some operations have a 3:rd column with an optional parameter. read and write tells you the number of bytes that were requested to be read or written. flushing tells you the number of bytes that were flushed from the disk cache.
This is an example excerpt from a log:
3702 idle 3706 check_fastresume 3707 idle 4708 save_resume_data 4708 idle 8230 read 16384 8255 idle 8431 read 16384
The script to parse this log and generate a graph is called parse_disk_log.py. It takes the log file as the first command line argument, and produces a file: disk_io.png. The time stamp is in milliseconds since start.
You can pass in a second, optional, argument to specify the window size it will average the time measurements over. The default is 5 seconds. For long test runs, it might be interesting to increase that number. It is specified as a number of seconds.

This is an example graph generated by the parse script.
disk_buffers.log
The disk buffer log tells you where the buffer memory is used. The log format has a time stamp, the name of the buffer usage which use-count changed, colon, and the new number of blocks that are in use for this particular key. For example:
23671 write cache: 18 23671 receive buffer: 3 24153 receive buffer: 2 24153 write cache: 19 24154 receive buffer: 3 24198 receive buffer: 2 24198 write cache: 20 24202 receive buffer: 3 24305 send buffer: 0 24305 send buffer: 1 24909 receive buffer: 2 24909 write cache: 21 24910 receive buffer: 3
The time stamp is in milliseconds since start.
To generate a graph, use parse_disk_buffer_log.py. It takes the log file as the first command line argument. It generates disk_buffer.png.
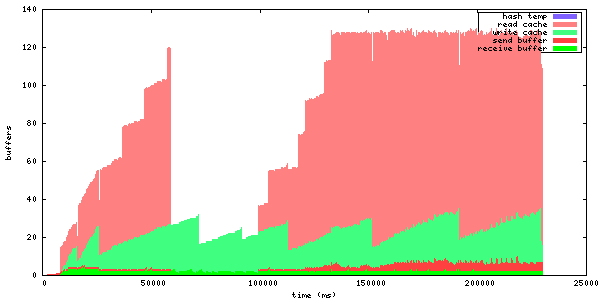
This is an example graph generated by the parse script.
disk_access.log
The disc access log has three fields. The timestamp (milliseconds since start), operation and offset. The offset is the absolute offset within the torrent (not within a file). This log is only useful when you're downloading a single torrent, otherwise the offsets will not be unique.
In order to easily plot this directly in gnuplot, without parsing it, there are two lines associated with each read or write operation. The first one is the offset where the operation started, and the second one is where the operation ended.
Example:
15437 read 301187072 15437 read_end 301203456 16651 read 213385216 16680 read_end 213647360 25879 write 249036800 25879 write_end 249298944 26811 read 325582848 26943 read_end 325844992 36736 read 367001600 36766 read_end 367263744
The disk access log does not have any good visualization tool yet. There is however a gnuplot file, disk_access.gnuplot which assumes disk_access.log is in the current directory.

The density of the disk seeks tells you how hard the drive has to work.
session stats
By defining TORRENT_STATS libtorrent will write a log file called session_stats/<pid>.<sequence>.log which is in a format ready to be passed directly into gnuplot. The parser script parse_session_stats.py generates a report in session_stats_report/index.html.
The first line in the log contains all the field names, separated by colon:
second:upload rate:download rate:downloading torrents:seeding torrents:peers...
The rest of the log is one line per second with all the fields' values.
These are the fields:
| field name | description |
|---|---|
| second | the time, in seconds, for this log line |
| upload rate | the number of bytes uploaded in the last second |
| download rate | the number of bytes downloaded in the last second |
| downloading torrents | the number of torrents that are not seeds |
| seeding torrents | the number of torrents that are seed |
| peers | the total number of connected peers |
| connecting peers | the total number of peers attempting to connect (half-open) |
| disk block buffers | the total number of disk buffer blocks that are in use |
| unchoked peers | the total number of unchoked peers |
| num list peers | the total number of known peers, but not necessarily connected |
| peer allocations | the total number of allocations for the peer list pool |
| peer storage bytes | the total number of bytes allocated for the peer list pool |
This is an example of a graph that can be generated from this log:
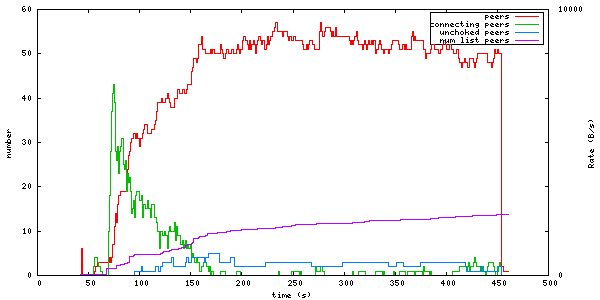
It shows statistics about the number of peers and peers states. How at the startup there are a lot of half-open connections, which tapers off as the total number of peers approaches the limit (50). It also shows how the total peer list slowly but steadily grows over time. This list is plotted against the right axis, as it has a different scale as the other fields.
understanding the disk thread
All disk operations are funneled through a separate thread, referred to as the disk thread. The main interface to the disk thread is a queue where disk jobs are posted, and the results of these jobs are then posted back on the main thread's io_service.
A disk job is essentially one of:
- write this block to disk, i.e. a write job. For the most part this is just a matter of sticking the block in the disk cache, but if we've run out of cache space or completed a whole piece, we'll also flush blocks to disk. This is typically very fast, since the OS just sticks these buffers in its write cache which will be flushed at a later time, presumably when the drive head will pass the place on the platter where the blocks go.
- read this block from disk. The first thing that happens is we look in the cache to see if the block is already in RAM. If it is, we'll return immediately with this block. If it's a cache miss, we'll have to hit the disk. Here we decide to defer this job. We find the physical offset on the drive for this block and insert the job in an ordere queue, sorted by the physical location. At a later time, once we don't have any more non-read jobs left in the queue, we pick one read job out of the ordered queue and service it. The order we pick jobs out of the queue is according to an elevator cursor moving up and down along the ordered queue of read jobs. If we have enough space in the cache we'll read read_cache_line_size number of blocks and stick those in the cache. This defaults to 32 blocks.
Other disk job consist of operations that needs to be synchronized with the disk I/O, like renaming files, closing files, flushing the cache, updating the settings etc. These are relatively rare though.
contributions
If you have added instrumentation for some part of libtorrent that is not covered here, or if you have improved any of the parser scrips, please consider contributing it back to the project.
If you have run tests and found that some algorithm or default value in libtorrent is suboptimal, please contribute that knowledge back as well, to allow us to improve the library.
If you have additional suggestions on how to tune libtorrent for any specific use case, please let us know and we'll update this document.