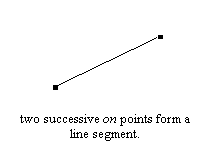1. Pixels, Points and Device Resolutions :
Though it is a very common assumption when dealing with computer graphics programs, the physical dimensions of a given pixel (be it for screens or printers) are not squared. Often, the output device, be it a screen or printer exhibits varying resolutions in the horizontal and vertical directions, and this must be taken care of when rendering text.It is thus common to define a device's characteristics through two numbers expressed in dpi (dots per inch). For example, a printer with a resolution of 300x600 dpi has 300 pixels per inch in the horizontal direction, and 600 in the vertical one. The resolution of a typical computer monitor varies with its size (a 15" and 17" monitors don't have the same pixel sizes at 640x480), and of course the graphics mode resolution.
As a consequence, the size of text is usually given in points, rather than device-specific pixels. Points are a simple physical unit, where 1 point = 1/72th of an inch, in digital typography. As an example, most roman books are printed with a body text which size is chosen between 10 and 14 points.
It is thus possible to compute the size of text in pixels from the size in points through the following computation :
pixel_size = point_size * resolution / 72
Where resolution is expressed in dpi. Note that because the horizontal and vertical resolutions may differ, a single point size usually defines different text width and height in pixels.
IMPORTANT NOTE:
Unlike what is often thought, the "size of text in pixels" is not directly related to the real dimensions of characters when they're displayed or printed. The relationship between these two concepts is a bit more complex and relate to some design choice made by the font designer. This is described in more details the next sub-section (see the explanations on the EM square).
2. Vectorial representation :
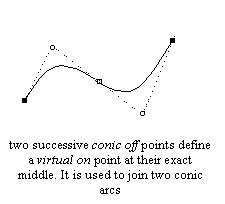
The source format of outlines is a collection of closed paths called contours. Each contour delimits an outer or inner region of the glyph, and can be made of either line segments or bezier arcs.The arcs are defined through control points, and can be either second-order (these are "conic beziers") or third-order ("cubic" beziers) polynomials, depending on the font format. Hence, each point of the outline has an associated flag indicating its type (normal or control point). And scaling the points will scale the whole outline.
Each glyph's original outline points are located on a grid of indivisible units. The points are usually stored in a font file as 16-bit integer grid coordinates, with the grid origin's being at (0,0); they thus range from -16384 to 16383. (even though point coordinates can be floats in other formats such as Type 1, we'll restrict our analysis to integer ones, driven by the need for simplicity..).
IMPORTANT NOTE:
The grid is always oriented like the traditional mathematical 2D plane, i.e. the X axis from the left to the right, and the Y axis from bottom to top.In creating the glyph outlines, a type designer uses an imaginary square called the "EM square". Typically, the EM square can be thought of as a tablet on which the character are drawn. The square's size, i.e., the number of grid units on its sides, is very important for two reasons:
it is the reference used to scale the outlines to a given text dimension. For example, a size of 12pt at 300x300 dpi corresponds to 12*300/72 = 50 pixels. This is the size the EM square would appear on the output device if it was rendered directly. In other words, scaling from grid units to pixels uses the formula: pixel_size = point_size * resolution / 72
pixel_coordinate = grid_coordinate * pixel_size / EM_sizeNote that glyphs can freely extend beyond the EM square if the font designer wants so. The EM is used as a convenience, and is a valuable convenience from traditional typography.the greater the EM size is, the larger resolution the designer can use when digitizing outlines. For example, in the extreme example of an EM size of 4 units, there are only 25 point positions available within the EM square which is clearly not enough. Typical TrueType fonts use an EM size of 2048 units (note: with Type 1 PostScript fonts, the EM size is fixed to 1000 grid units. However, point coordinates can be expressed in floating values). Note : Grid units are very often called "font units" or "EM units".
NOTE:
As said before, the pixel_size computed in the above formula does not relate directly to the size of characters on the screen. It simply is the size of the EM square if it was to be displayed directly. Each font designer is free to place its glyphs as it pleases him within the square. This explains why the letters of the following text have not the same height, even though they're displayed at the same point size with distinct fonts :
As one can see, the glyphs of the Courier family are smaller than those of Times New Roman, which themselves are slightly smaller than those of Arial, even though everything is displayed or printed at a size of 16 points. This only reflect design choices.
3. Hinting and Bitmap rendering
The outline as stored in a font file is called the "master" outline, as its points coordinates are expressed in font units. Before it can be converted into a bitmap, it must be scaled to a given size/resolution. This is done through a very simple transform, but always creates undesirable artifacts, e.g. stems of different widths or heights in letters like "E" or "H".As a consequence, proper glyph rendering needs the scaled points to be aligned along the target device pixel grid, through an operation called "grid-fitting", and often "hinting". One of its main purpose is to ensure that important widths and heights are respected throughout the whole font (for example, it is very often desirable that the "I" and the "T" have their central vertical line of the same pixel width), as well as manage features like stems and overshoots, which can cause problems at small pixel sizes.
There are several ways to perform grid-fitting properly, for example most scalable formats associate some control data or programs with each glyph outline. Here is an overview :
explicit grid-fitting :The TrueType format defines a stack-based virtual machine, for which programs can be written with the help of more than 200 opcodes (most of these relating to geometrical operations). Each glyph is thus made of both an outline and a control program, its purpose being to perform the actual grid-fitting in the way defined by the font designer.
implicit grid-fitting (also called hinting) :The Type 1 format takes a much simpler approach : each glyph is made of an outline as well as several pieces called "hints" which are used to describe some important features of the glyph, like the presence of stems, some width regularities, and the like. There aren't a lot of hint types, and it's up to the final renderer to interpret the hints in order to produce a fitted outline.
automatic grid-fitting :Some formats simply include no control information with each glyph outline, apart metrics like the advance width and height. It's then up to the renderer to "guess" the more interesting features of the outline in order to perform some decent grid-fitting.
The following table summarises the pros and cons of each scheme :
|
|
|
|
|
|
|
|
|
|
|
|